在学习deep learning的过程中,我注意到大多数教程是关于计算机视觉和自然语言处理方面的。确实这些是深度学习取得成功的主要领域,但是很多时候我们想要处理的数据并不是图片,音频或者文本这样的比较简明结构清晰的数据,结构数据(Structured Data)是在现实中更加常见的数据类型,比如说企业的销售数据,保险数据,商店经营数据等。在学习Fastai课程的过程中我了解了一个概念-EmbeddingMatrix,可以很好的用来处理这类型的数据。
比如说在一个预测商品销售额的问题中,feature分成两种,一种叫做continuous data比如当天温度,和附近商店的距离等,这种类型的数据一般会当做浮点数处理;还有一种是categorical data,比如星期,月份。这种数据显然不适合像连续性数据一样当做浮点数处理,它们的值是可以穷举的,而且相邻的两个量,比如说周三,周四的销售额似乎没有什么数字上的联系。对于这种数据,我们可以设计一个Embedding Matrix来对这些量进行一个转换,然后把它们和其他连续型变量拼接在一起形成神经网络的Input data。
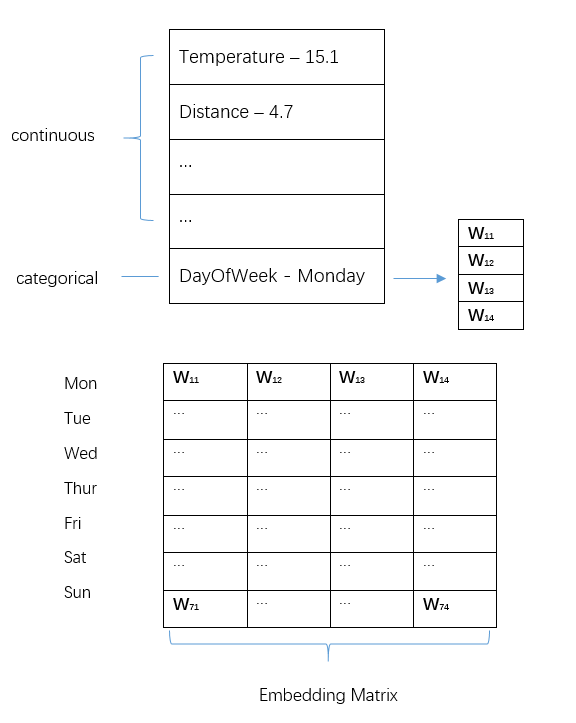
比如说上图,我们为星期这一特征建立一个Embedding Matrix行数为七,对应一周可能的七个值。列数可以自己设置,列数越大那么模型容量就越大,一个建议的经验法则是设置为min((n+1)/2,50),n为行数。
在这个EmbeddingMatrix中,每一行对应着我们
在输入向量中,continuous部分可以直接取其值(可能需要normalize)categorical部分则要先从EmbeddingMatrix中找出对应的行,把这行的权重与continuous部分的值拼接起来,然后作为完整的输入数据。比如说在图中的一组输入数据中,星期数为Monday,那么就从Embedding Matrix中Monday对应的一行抽取出来,Monday这里就替换成了四个可学习的参数,与其他输入数据拼接在一起送入神经网络去学习。在训练过程中,除了常规的神经网络中的参数以外,Embedding Matrix层的数据也会不断更新。
事实上,Embedding Matrix的行数往往会比可取值的数目多1,多的一行对应‘不存在’这一类别,因为实际上获取的真实数据不一定是所有信息都是完整的,对于缺失的数据,就都归为不存在这一栏。
参考链接:
[1]Fastai course partI:https://course.fast.ai/lessons/lesson4.html